知识蒸馏(Knowledge Distillation)
深度学习的主要挑战在于,受限制于资源容量,深度神经模型很难部署在资源受限制的设备上,如嵌入式设备和移动设备。知识蒸馏作为模型压缩和加速技术的代表,可以有效的从大型的教师模型中学习到小型的学生模型。

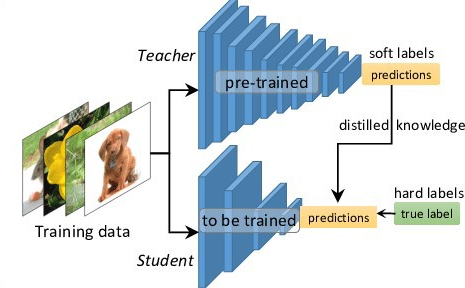
知识蒸馏主要思想是:学生模型模仿教师模型,二者相互竞争,是的学生模型可以与教师模型持平甚至卓越的表现。关键问题是如何将知识从大的教师模型转移到小的学生模型。知识蒸馏系统由知识、蒸馏算法和师生架构三个关键部分组成。如上图所示。
知识
在知识蒸馏中,知识可以分为基于响应的知识(response-based knowledge),基于特征的知识( feature-based knowledge), 基于关系的知识(relation-based knowledge),下图为教师模型中不同知识类别的直观示例。


基于响应的知识(Response-Based Knowledge)
基于响应的知识的主要思想是让学生网络直接模仿教师网络的最终预测。假设对数向量 $z$ 为全连接层的最后输出,基于响应的蒸馏形式可以描述为: $$ L_{ResD}(z_t,z_s)=L_R(z_t,z_s) $$ 其中 $L_R$ 表示散度损失或者交叉熵损失,典型的基于响应的知识蒸馏结构如下图所示。

最流行的基于响应的图像分类知识被称为软目标(soft target),软目标是输入的类别的概率,可以通过 softmax 函数估计为: $$ p(z_i,T)=\frac{\exp(z_i/T)}{\sum_j\exp(z_j/T)} $$ $z_i$ 为第i个类别的 logit,T 是温度因子,因此 soft logits 的知识蒸馏损失函数可以重写为: $$ L_{ResD}(p(z_t,T),p(z_s,T))=L_R(p(z_t,T),p(z_s,T)) $$ 通常,$L_R$ 使用 KL 散度损失。基于响应的知识通常需要依赖最后一层的输出,无法解决来自教师模型的中间层面的监督,而这对于使用非常深的神经网络进行表征学习非常重要。由于 logits 实际上是类别概率分布,因此基于响应的知识蒸馏限制在监督学习。
下图为基准的知识蒸馏的具体网络架构。可见,知识蒸馏的损失函数为教师与学生网络在温度T下的蒸馏损失和学生网络输出与GT在温度1下的学生损失。

温度的设置
模型在训练收敛后,softmax的输出不会是完全符合one-hot向量那种极端分布的,而是在各个类别上均有概率,即教师模型中在这些负类别(非正确类别)上输出的概率分布包含了一定的隐藏信息。在使用softmax的时候往往会将一个差别不大的输出变成很极端的分布,用一个三分类模型的输出举例: $$ [10,11,12]\rightarrow[0.0900,0.2447,0.6652] $$ 原本的分布很接近均匀分布,但经过softmax,不同类别的概率相差很大。这就导致类别间的隐藏的相关性信息不再那么明显。为了解决这个问题,引入温度系数。
对于随机生成的分布:$z\in\mathbb{R}^{10}\sim N(10,2)$,在不同温度下,数据分布的变化情况如下图所示:

对于蒸馏温度T,如果T接近于0,则最大值接近1,其他值接近0,近似于 argmax;如果T越大,则输出分布越平缓,相当于平滑的作用,保留相似信息。
在蒸馏时,令教师与学生模型的损失为$L_1$,学生模型与真实标签之间的损失为$L_2$。$L_1$可以看做是引入的正则项,能够使得学生模型学到教师模型中高度泛化的知识,从而需要更少的训练样本即可收敛。
$L_1$项始终使用较大的温度系数,$L_2$项使用较小的温度系数。这是由于温度系数较大时,模型需要训练得到一个很陡峭的输出,经过softmax之后才能获得一个相对陡峭的结果;温度系数较小时,模型输出稍微有点起伏,softmax就很敏感地把分布变得尖锐,认为模型学到了知识。
基于特征的知识(Feature-Based Knowledge)
深度神经网络善于学习到不同层级的表征,因此中间层和输出层的都可以被用作知识来监督训练学生模型,中间层的知识对于输出层的知识是一个很好的补充。其蒸馏损失可以表示为: $$ L_{FeaD}(f_t(x),f_s(x))=L_F(\Phi_t(f_t(x)),\Phi_s(f_s(x))) $$ 其中 $f_t(x),f_s(x)$ 分别表示教师和学生网络的中间层特征图。变换函数 $\Phi(\cdot)$ 当特征图大小不同时应用,$L_F$ 衡量两个特征图的相似性,常用的有 L1, L2, 交叉熵等。下图为基于特征的知识蒸馏模型的架构。

基于关系的知识(Relation-Based Knowledge)
基于响应和基于特征的知识都使用了教师模型中特定层的输出,基于关系的知识进一步探索了不同层或数据样本的关系。一般,将基于特征图关系的关系知识蒸馏loss表述如下: $$ L_{RelD}(f_t,f_s)=L_{R}(\Psi_t(\hat{f_t},\check{f_t}),\Psi_s(\hat{f_s},\check{f_s})) $$ 其中,$f_t,f_s$ 表示教师和学生网络的特征图,$(\hat{f_t},\check{f_t})$ 和 $(\hat{f_s},\check{f_s})$ 表示教师和学生网络的特征图组(pair),$\Psi(\cdot)$ 函数表示特征图组的相似性。

蒸馏策略(Distillation Schemes)
根据教师模型是否与学生模型同时更新,知识蒸馏的学习方案可分为离线蒸馏(offline distillation)、在线蒸馏(online distillation)和自蒸馏(self-distillation)。
从人类师生学习的角度也可以直观地理解离线、在线和自蒸馏。离线蒸馏是指知识渊博的教师教授学生知识;在线蒸馏是指教师和学生一起学习;自我蒸馏是指学生自己学习知识。

离线蒸馏(Offline Distillation)
离线蒸馏包括两个阶段:1)大型教师模型蒸馏前在训练集上训练;2)教师模型在蒸馏过程中指导学生模型训练。
离线蒸馏方法有训练时间长、复杂等缺点,而在教师模型的指导下,离线蒸馏中的学生模型的训练通常是有效的。此外,教师与学生之间的能力差距始终存在,而且学生往往对教师有极大依赖。
在线蒸馏(Online Distillation)
为了克服离线蒸馏的局限性,提出了在线蒸馏来进一步提高学生模型的性能。在线蒸馏时,教师模型和学生模型同步更新,而整个知识蒸馏框架都是端到端可训练的。
自蒸馏(Self-Distillation)
在自蒸馏中,教师和学生模型使用相同的网络,这可以看作是在线蒸馏的一个特例,例如将网络深层的知识蒸馏到浅层部分。
教师学生结构(Teacher-Student Architecture)
学生网络的结构通常有以下选择:
- 教师网络的简化版本,层数更少,每一层的通道数更少;
- 保留教师网络的结构,学生网络为其量化版本;
- 具有高效基本运算的小型网络;
- 具有优化全局网络结构的小网络;
- 与教师网络的结构相同.
教师和学生网络的关系如下图。

蒸馏算法(Distillation Algorithms)
对抗性蒸馏(Adversarial Distillation)
多教师蒸馏(Multi-teacher Distillation)
跨模态蒸馏(Cross-Modal Distillation)
基于图的蒸馏(Graph-Based Distillation)
基于注意力的蒸馏(Attention-Based Distillation)
无数据的蒸馏(Data-Free Distillation)
量化蒸馏(Quantized Distillation)
终身蒸馏(Lifelong Distillation)
基于神经架构搜索的蒸馏(NAS-Based Distillation)