动机与介绍
已有方法对跨域数据集和高压缩高曝光数据的检测能力大幅下降(泛化性差);
难以识别的fake样本通常包含更一般伪造痕迹,故要学习更通用和鲁棒的面部伪造表征;
定义了四种常见的伪影(artifacts):

主要贡献
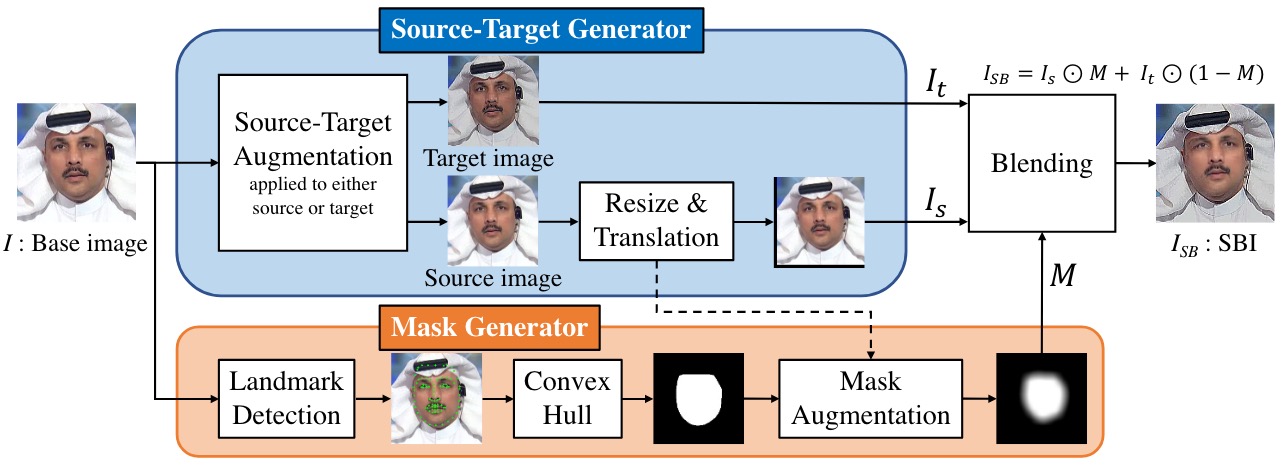
- 提出了source-target generator (STG) and mask generator (MG)来学习更一般鲁棒的人脸伪造表征
- 通过自换脸而非寻找最接近的landmark换脸,降低了计算成本
- 在cross-dataset和cross-maniputation测试中都取得了SOTA

方法
学习伪造人脸与背景的不一致分为下列三个模块
Source-Target Generator(STG):
- 对source和target进行数据增强以产生不一致,并且对source进行resize和translate以再现边界混合和landmarks不匹配;
- 首先对Target和Source之一做图像增强 (color:RGB channels, hue, saturation, value, brightness, and contrast;frequency:downsample or sharpen);
- 然后对source进行裁剪:$H_r=u_hH,\quad W_r=u_wW$,其中$\ u_h和u_w$是一组均分分布中的随机值,再对裁剪后的图像zero-padded 或者 center-cropped还原回初始大小;
- 最后对source做变形(translate):traslate vector$\ t=[t_h,t_w]$,$\ t_h=v_hH,t_w=v_wW$,$v_h和v_w$是一组均分分布中的随机值。
Mask Generator: 生成变形的灰度mask图
- 计算面部landmarks的convex hull来初始化mask,然后对mask变形(elastic deformation),在用两个不同参数的高斯滤波器(gaussian filter)对mask进行平滑处理。最后在{0.25, 0.5, 0.75, 1, 1, 1}中选取混合指数(blending ration);
Blending: 用Mask来混合source和target图得到SBI
$$I_{SB}=I_s\odot M+I_t\odot(1-M)$$

Train with SBIs: 将target而非原图作为”REAL“,使得模型集中在伪造痕迹上
实验
- 实现细节
- 预处理:Dlib和RetinaFace裁帧,面部区域裁剪:4~20%(训练),12.5%(推理);
- Source-Target Augmentation:RGBShift, HueSaturationValue, RandomBrightnessContrast, Downscale, and Sharpen
- 推理策略:如果在一帧中检测到两个或多个人脸,则将分类器应用于所有人脸,并将最高的虚假置信度用作该帧的预测置信度。
- 实验设定:各类baseline
- 跨数据集评估

- 跨操作评估

- 定量分析


- 消融实验



- 定性分析
局限性
缺乏时序信息、无法解决GAN生成的伪造图像