摘要
显式建模生成由人脸运动产生的运动失真;使用逆渲染从视频帧中获取人脸和环境光照的3D形状和反照率然后渲染每一帧人脸。利用生成的运动扰动对运动诱导的测量值进行滤波。信号质量提高2dB;激烈运动场景心率估计RMSE提高30%。
1. Introduction
来自相机的rPPG信号具有极低的信号强度,并且受到传感器噪声和运动伪影的影响。目前方法大多无法处理剧烈运动产生的运动伪影,仅限于实验室环境使用。
我们使用双向LSTM生成运动伪影来过滤运动诱导的rPPG信号。
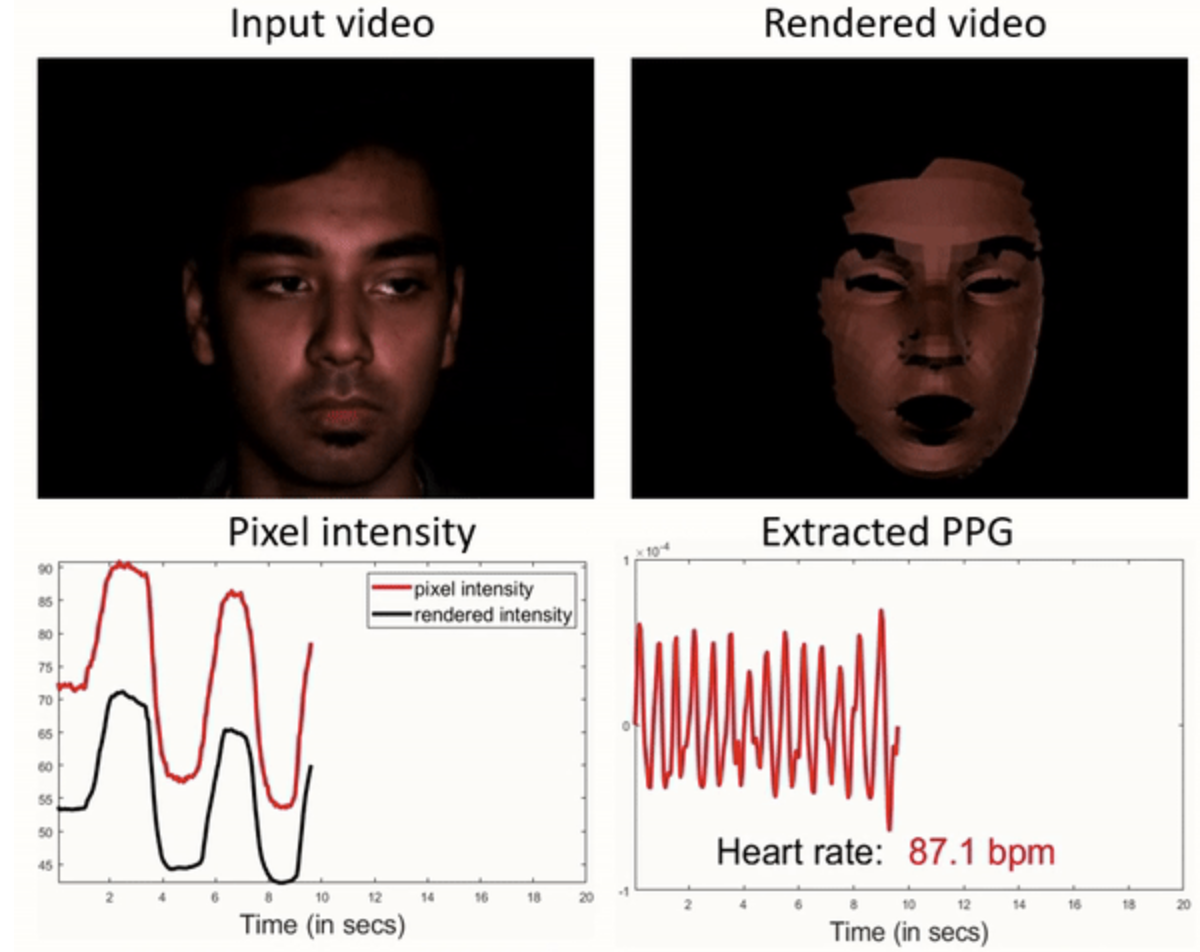
如下图所示:(a)输入参考视频帧; (b)基于估计的3D形状和光照渲染人脸; (c)对参考帧注册连续帧; (d)从(a)中测量人脸上一个跟踪点的像素强度变化; (e)运动信号,使用生成的运动信号抵消运动扰动,从而在(f)中产生干净的信号,红线表示实际心率。

为了生成运动扰动,需要知道人脸几何形状和光照;人脸几何形状可以通过深度估计相机来获得;光照信息需要在相同环境下进行预校准。在实际场景中这几乎是不可行的。
通过使用3D FaceMesh模型来获得人脸的三维几何结构,该模型给出了人脸在每个时刻的近似几何结构。其次,基于一个近似的三维人脸几何图形,使用序列帧来估计场景光照。
主要贡献如下:
开发了一个框架,使用通过反向渲染来估计的3D人脸模型和场景光照,显式地建模基于相机的rPPG信号中的运动扰动。我们使用生成的运动信号,通过双向LSTM过滤rPPG信号中的运动扰动,得到干净的信号。
实验表明该方法在提取的rPPG信号质量和估计的心率精度方面优于SOTA。RobustPPG在复杂运动场景下的信号质量提高了2dB以上,在剧烈运动场景下的心率估计比次优方法提高了33%。
使用一个扩展的光度立体装置来验证pipeline。FaceMesh生成的表面法线与光度立体法生成的表面法线GT平均偏离13°。表明即使采用近似的人脸几何估计,使用FaceMesh估计的运动信号与GT运动信号的归一化均方根误差也小于10%。在rPPG信号提取方面,FaceMesh生成的3D人脸几何图形获得了近乎最优的性能。
2. 背景和挑战
主要目标是开发一种鲁棒的算法来从视频中皮肤像素强度波动中恢复rPPG信号,然后从rPPG信号中估计心率。

以下原因导致获得运动扰动信息是困难的:
运动扰动依赖于面部局部方向:如上图a),即使分别跟踪人脸的不同区域,运动扰动也不同
运动扰动依赖于光照环境:如上图b),对于人脸上的同一点的相同运动,不同光照方向下的强度变化也不同
3. 方法
在这项工作中,利用逆渲染 (Inverse Rendering) 来显式地从视频中生成运动扰动。

如图,首先用3D人脸跟踪器FaceMesh获取每帧人脸的3D形状,然后估计光照方向,并在每个三角形局部区域生成精确的运动扰动。最后在双向LSTM中同时利用愚弄当心好和损耗的原生像素强度波动来获得干净的rPPG信号。
3.1 运动信号模型
根据二色反射模型 (Dichromatic Reflection Model, DRM),人脸任意3D位置r在t时刻的RGB像素强度可以描述为漫反射和镜面反射分量之和:
$$ \mathrm{i}(\mathrm{r},t)=\mathrm{i}_{\text{diffuse}}+\mathrm{i}_{\text{specular}} $$
$\mathrm{i}_{\text{diffuse}}$ 和 $\mathrm{i}_{\text{specular}}$均$\in\mathbb{R}^{3\times1}$。
如下图,我们做出以下假设:
光源为远离人脸的点光源,且与相机的位置保持不变。因此在所有位置上均为平行光,且光源强度保持恒定
人脸具有Lambertian反射,在Lambertian假设下,所有点源可以建模为一个点源

在这个假设下有:
$$ \mathbf{i}(\mathbf{r},t)=\mathbf{c}*\mathbf{n}(\mathbf{r},t)\cdot \mathbf{l}+\mathbf{e}*p(t)\odot(\mathbf{c}*\mathbf{n}(\mathbf{r},t)\cdot \mathbf{l})\tag{1} $$
3.2 生成运动信号
要从上述公式中提取搏动的血容量信号$p(t)$,需要生成运动扰动。需要三个参数:表面法线$\mathbf{n(r},t)$;有效光源方向$\mathbf{I}$;随时间保持不变的平均肤色$\mathbf{c}$
3.2.1 3D 人脸建模
使用FaceMesh在视频的每一帧进行人脸跟踪和拟合。
首先在每一帧中检测并跟踪人脸,然后检测每一帧的人脸特征点;
然后利用3DMM (3D Morphable Models) 进行人脸拟合,生成3D人脸几何形状和纹理,生成稠密的三角形网络,如下图,计算每个三角形像素强度的平均值;
因此,对于每一个视频,有表面法向量$\mathbf{N}\in\mathbb{R}^{K\times T\times 3}$,K是每一帧中的三角形数,T是帧数,3表示xyz三个空间分量。强度$\mathbf{I}\in\mathbb{R}^{K\times T\times 3}$,3表示RGB通道像素强度。

3.2.2 光照估计
对于一序列帧,剔除高光、嘴唇和头发区域,使用面上所有三角网络的测量值估计光源方向。上面的公式(1)中忽略rPPG部分,有:
$$ \mathbf{I}=\mathbf{N}*\mathbf{l}*\mathbf{c}^\intercal $$
其中$\mathbf{I}\in\mathbb{R}^{K\times T_w\times 3}$是像素强度,$\mathbf{N}\in\mathbb{R}^{K\times T_w\times 3}$为表面法线方向,$T_w$为帧数。需要估计有效光源方向$\mathbf{l}\in\mathbb{R}^{3\times1}$和评价肤色(假设不同位置肤色相同)$\mathbf{c}\in\mathbb{R}^{3\times 1}$
3.2.3 生成信号矩阵
如下图所示,在估计有效光照方向$\mathbf{\widehat{I}}$和平均肤色$\mathbf{\widehat{c}}$后,生成每个三角区域$\mathbf{r}$的运动信号$\mathbf{m(r},t)$:
$$ \mathbf{m(r},t)=\mathbf{\widehat{c}}*\mathbf{n(r},t)\cdot\mathbf{\widehat{I}}=(\mathbf{n(r},t)^\intercal*\mathbf{\widehat{I}}*\mathbf{\widehat{c}}^\intercal)^\intercal $$

因此,对于每个三角区域,能够得到六个信号:RGB像素强度$(i_{r}(t),i_{g}(t),i_{b}(t))$和RGB运动信号$(m_r(t),m_g(t),m_b(t))$,重写公式(1)得到时序运动扰动$m$的函数:
$$ \mathbf{i}(\mathbf{r},t)=\mathbf{m}(\mathbf{r},t)+e*p(t)\odot\mathbf{m}(\mathbf{r},t)\tag{2} $$
其中$\mathbf{i}(\mathbf{r},t)$是有干扰的rPPG信号,$\mathbf{m}(\mathbf{r},t)$是运动扰动信号$p(t)$是干净的rPPG信号。使用生成的运动信号,构造信号特征矩阵
$$ S_r=[i_{r}(t),i_{g}(t),i_{b}(t),m_r(t),m_g(t),m_b(t)]^\intercal\in\mathbb{R}^{6\times t} $$
3.3 rPPG信号的运动抵消
将$S_r$输入Bi-LSTM,接触的脉冲器波形作为标签进行训练。
对于该架构,使用包含30隐藏单元的3层的Bi-LSTM网络。将信号划分为4秒的窗口,重叠部分为2秒,作为输入,损失函数为MSE。
4 实验
4.1 FaceMesh 验证
FaceMesh 面部跟踪器决定了光照估计的准确率和运动信号生成的质量。
人脸几何形状的准确性
光照方向的误差
运动信号的质量
不准确的运动信号生成对rPPG信号的影响
4.1.1 光度立体设置
使用光度立体来获取运动中的真实3D人脸几何形状。
4.2 3D 面部几何形状估计

如上图。在鼻子区域的角度误差最大;平均角误差(除去眼睛鼻子和嘴巴区域)在人脸模型和真人上分别为$13.8^\circ, 18.37^\circ$
在上图的下半部分,展示了旋转过程中人脸模型前额上一个三角形和说话场景下真人的角误差。
4.3 光照估计准确率
用FaceMesh得到的三维几何结构来获得光照矩阵的估计值$\mathbf{\widehat{U}}$。在四个人体模型上平均误差为$4.56^\circ$。
4.4 运动信号生成
下图展示了一个由光度立体和FaceMesh生成的0运动信号和来自单个三角形的实际像素强度的例子。第三行滤波后的残余信号不包含强信号,说明成功去除了运动信号。

然后用带通滤波器$([0.5-5]Hz)$对运动信号滤波(人体心率属于这一频率范围)。计算两个指标:1)归一化方根误差(NRMSE);2)人体模型视频中估计的运动信号和实际像素强度之间的归一化互相关(normalized cross-correlation, NCC)。如下表:

4.5 rPPG信号估计
使用光度立体生成的运动信号在估计rPPG信号的平均信噪比方面,与FaceMesh相比,没有显著提高(0.15dB,p>0.005)。因此,使用FaceMesh生成的运动信号在rPPG信号估计方面达到了接近最优的性能。
5 PPG信号估计
5.1 数据集
PURE数据集包含10名被试在6种运动条件下同步生理数据的人脸视频,包括头部转动和说话。视频时长约为1 min,真值PPG波形由接触式脉搏血氧监测仪提供。
为了验证在剧烈运动场景下的性能,创建了一个单独的数据集RICE-motion,包括12名受试者的72段视频(9男3女),包含快速的头部旋转动作和自然表情说话场景。
5.2 训练和验证运动消除网络
将信号特征矩阵$S_r$作为Bi-LSTM的输入,模型学习像素强度变化和运动扰动信号与PPG信号关联的函数。由于真实数据集较小,通过在rPPG信号中生成各种运动扰动来生成一个合成数据集用于训练。
合成数据集:使用公式(2)来合成信号矩阵。使用参数化模型来生产干净的PPG信号$p(t)$,心率从30bpm到240bpm均匀分布中随机选取,生成一个30s的干净PPG信号。使用随机布朗噪声生成器(random Brownian noise generator)来生产运动信号$\mathbf{m}(t)$。最后,在像素强度中添加随即白噪声来模拟建模误差和相机传感器误差。参数$\mathbf{e}_{ppg}=[0.18,0.78,0.60]$保持恒定。生成了400个运动信号$\mathbf{m}(t)$,与合成的RGB信号强度$\mathbf{i}(t)$一起合成信号矩阵$S_r$。
对信号进行标准化(减均值除标准差),然后用带通滤波器$([0.5~5])Hz$进行滤波。
将模型预测的rPPG信号从面部所有三角形位置进行空间平均,得到整体rPPG信号。
5.3 性能比较
计算不同方法提取的rPPG信号的信噪比来评估PPG信号的质量。
基于提取的rPPG信号计算心率,使用5秒和1秒的短重叠窗口来计算瞬时心率,然后计算心率与真值的RMSE。
5.4 结果和讨论

上图为两个数据集中原始的rPPG信号和生成的运动信号。
下表报告了PURE数据集里所有受试者六种运动的平均SNR值。对于静态或平稳简单的运动,所有方法SNR相对一致;在说话等复杂的面部动作中,所有方法的SNR都会下降。其次,RobustPPG在所有运动场景下的表现优于其他方法且在会话场景下的优势最大。

展示下图方法估计的血容量信号相较于PURE和RICE-motion数据集的真值频谱图。可以观察到,RobustPPG方法估计的心率信号比其他方法更干净,且上表表明RobustPPG能够提供给更可靠的心率变异性(heart rate variability, HRV)和平均心率测量。

下表为在更具挑战性的RICE-motion数据集上的SNR值和心率的RMSE值。

此外,还通过测试在室内和室外手机视频上评估RobustPPG方法,如下图所示。RobustPPG估计的频谱图在预期心率频带内有较强的信号成分和更少的扰动,且有着更高的SNR,展现了在不同光照条件下更强的鲁棒性。

此外,下表展示了有无胡须和不同肤色的测试结果。
| SNR(dB) | RMSE(bpm) | |
|---|---|---|
| 有胡须 | 4.75 | 2.31 |
| 无胡须 | 5.16 | 1.92 |
| 白色皮肤 | 5.89 | 2.33 |
| 橄榄色皮肤 | 4.96 | 2.94 |
在训练时使用手指的PPG信号作为标签,但相对于面部PPG信号,手指PPG信号1)具有更多的特征和更高的谐波;2)并且由于脉冲传输产生相位延迟。通过对指脉波形进行低通滤波解决第一个问题;相位延迟问题较难解决。
RobustPPG有4个部分:1)人脸跟踪;2)表面法线、像素强度波动提取和光照估计;3)运动信号生成;使用Bi-LSTM网络提取每个三角网格处的rPPG信号。计算瓶颈在从每一帧图像中提取每个三角网格处的像素强度。
6 总结和展望
我们提出了一种新的算法RobustPPG用于基于摄像头的rPPG信号提取和心率估计。我们证明了像FaceMesh这样的3D人脸跟踪器可以在像素强度变化的情况下产生精确的运动失真。此外,使用Bi-LSTM网络进行信号滤波,我们在rPPG信号提取中表现出比现有方法更好的准确性。我们希望这项工作将大大推动运动鲁棒性的极限,以实现可靠的心率估计,并能将其应用到现实生活中。
在本工作中,我们仅对Lambertian建模引起的运动畸变进行建模。可以考虑镜面成分,使建模更加准确。其次,我们在工作中只考虑了远距离照明的假设。近光场景要求建模的复杂性可以被探索以更好地估计运动信号。第三,我们还考虑了相机固定的情况。摄像头的移动会造成rPPG信号中额外的信号失真,这可能会影响手持电话场景下心率估计的准确性。这些都是值得探索的有趣途径,或许可以作为未来工作的令人兴奋的方向。